内存、磁盘、数据库索引采用B+树缘由
泛域名ssl证书 239元1年送1个月、单域名39元1年,Sectigo(原Comodo证书)全球可信证书,强大的兼容性,高度安全性,如有问题7天内可退、可开发票
加微信VX 18718058521 备注SSL证书
【腾讯云】2核2G4M云服务器新老同享99元/年,续费同价
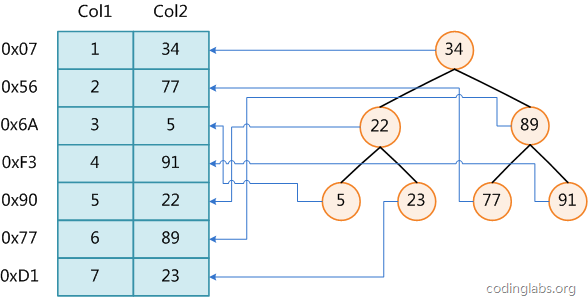
主存存取原理
目前计算机使用的主存基本都是随机读写存储器(RAM),现代RAM的结构和存取原理比较复杂,这里抽象出一个十分简单的存取模型来说明RAM的工作原理。

从抽象角度看,主存是一系列的存储单元组成的矩阵,每个存储单元存储固定大小的数据。每个存储单元有唯一的地址,现代主存的编址规则比较复杂,这里将其简化成一个二维地址:通过一个行地址和一个列地址可以唯一定位到一个存储单元。上图展示了一个4 x 4的主存模型。
主存的存取过程如下:
当系统需要读取主存时,则将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上,供其它部件读取。
写主存的过程类似,系统将要写入单元地址和数据分别放在地址总线和数据总线上,主存读取两个总线的内容,做相应的写操作。
这里可以看出,主存存取的时间仅与存取次数呈线性关系,因为不存在机械操作,两次存取的数据的“距离”不会对时间有任何影响,例如,先取A0再取A1和先取A0再取D3的时间消耗是一样的。
磁盘存取原理
上文说过,索引一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的。
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)。在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存取一个磁盘的内容。磁头不能转动,但是可以沿磁盘半径方向运动(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。为了简单起见,我们下面假设磁盘只有一个盘片和一个磁头。
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间(耗时最长),然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间,之后从磁盘读出或将数据写入磁盘的时间叫做传输时间。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
空间局部性原理:一旦一个指令一个存储单元被访问,那么它附近的单元也将很快被访问。
时间局部性原理:一旦一个指令被执行了,则在不久的将来,它可能再被执行
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页的大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1(h为层数)次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
但是由于B树的索引还存储了数据文件,每个节点(页)的存储索引容量更小,也就是出度d没法变得很大,相对于B+树而言,B+树由于每个节点只是存储索引,所以对于4k大小的页可以存储很多的索引,这种方式效率更高,可以更有效降低I/O次数(按照聚集索引的存储方式解释也可以)
为什么数据库使用B+树进行存储?
关系数据库的索引设计就是为了实现访问磁盘块数最少, 由于每个数据库中的数据量都很大,相应的索引文件也会很大,肯定会分布在多个磁盘块上,并且不能保证是连续的。 所以数据库在存储索引的时候,一个重要的目标就是: 读取索引时访问的磁盘块次数尽可能地少!
这该怎么实现呢? B+树就上场了:
B+树中间节点不保存数据,只保存key和指针 (这样就可以保存很多)
B+树叶子节点保存真正的数据(上图的黄色小方块),叶子节点还是有序的,互相链接的,方便范围查询。
使用B+树,可以让这个树的高度很低,2~3层就可以了,我们来计算一下:
InnoDB 存储引擎一个数据页是16K, 每个中间节点保存了若干个key + 指针
假设每个中间节点中key是4个字节,指针6个字节, 那每个中间节点能保存 16K/(4+6)= 1638个指针。
假设叶子节点中每条记录占据1K,那每个叶子节点可以保存 16K/1K = 16 条记录
那么一个两层高的B+树就可以保存 1638 *16 = 26,208 条记录
三层高的B+树就可以保存 1638* 1638 * 16 = 42,928,704 条记录。
也就是只需要3层,就可以保存4千多万条数据。
树的高度低,那就意味着IO次数少,访问起来就快了。
————————————————
版权声明:本文为CSDN博主「Chackca」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35642036/article/details/82809932